
 成为VIP
成为VIP
一、主从复制架构简介
通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构。那么,我们首先来了解一下神马是主从复制架构?
1.1 源于关系数据库的读写分离
随着网站业务的不断发展,用户量的不断增加,数据量也成倍的增长,数据库的访问量也呈线性地增长。特别是在用户访问高峰期间,并发访问量突然增大,数据库的负载压力也会增大,如果架构方案不够健壮,那么数据库服务器很有可能在高并发访问负载压力下宕机神马快照排名,造成数据访问服务的失效,从而导致网站的业务中断,给公司和用户造成双重损失。那么,有木有一种方案能够解决此问题,使得数据库不再因为负载压力过高而成为网站的瓶颈呢?答案肯定是有的。
目前,大部分的主流关系型数据库都提供了主从热备功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。
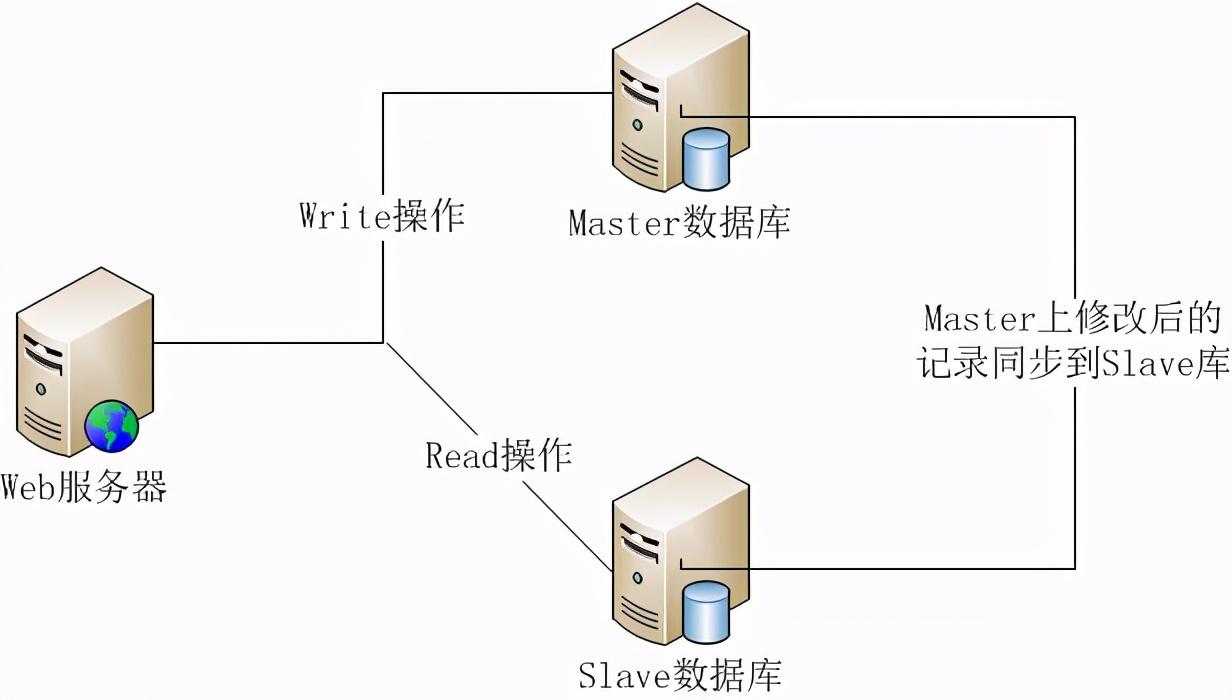
利用数据库的读写分离,Web服务器在写数据的时候,访问主数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样当Web服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的Web应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
1.2 基于MySQL的数据复制流程
刚刚我们了解了关系型数据库的读写分离能够实现数据库的主从架构,那么主从架构中最重要的数据复制又是怎么一回事呢?MySQL作为最流行的关系型数据库之一,通过了解MySQL的数据复制流程,会使得我们对Redis主从复制的认知会有一定的帮助。
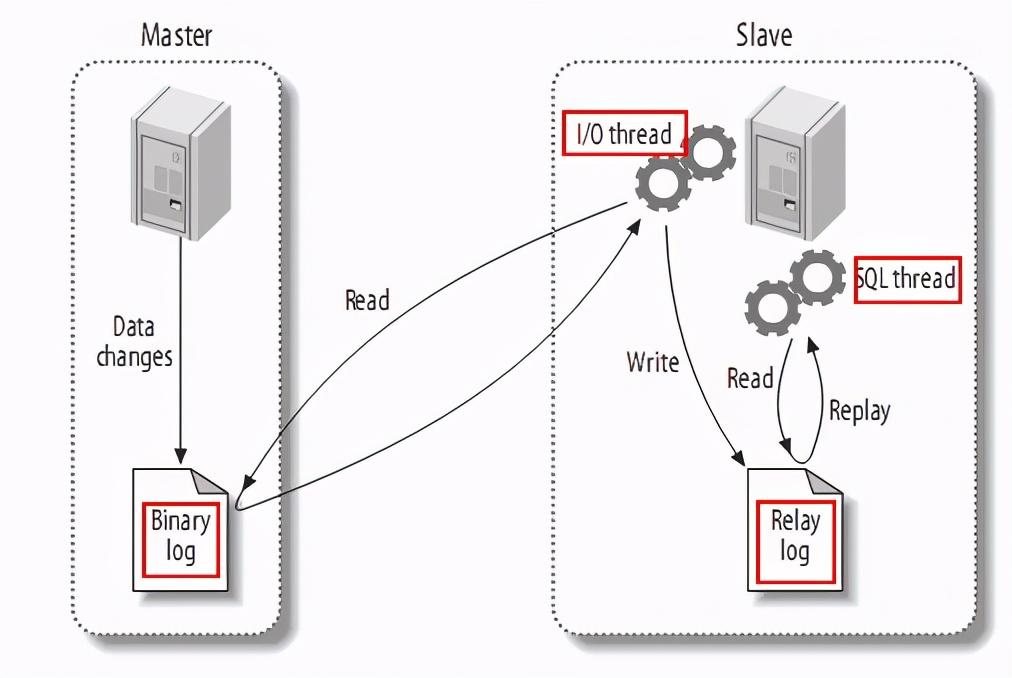
从上图来看,整体上有如下三个步凑:
(1)Master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2)Slave将Master的二进制日志事件(binary log events)拷贝到它的中继日志(relay log);
PS:从图中可以看出,Slave服务器中有一个I/O线程(I/O Thread)在不停地监听Master的二进制日志(Binary Log)是否有更新:如果没有它会睡眠等待Master产生新的日志事件;如果有新的日志事件(Log Events),则会将其拷贝至Slave服务器中的中继日志(Relay Log)。
(3)Slave重做中继日志(Relay Log)中的事件,将Master上的改变反映到它自己的数据库中。
PS:从图中可以看出,Slave服务器中有一个SQL线程(SQL Thread)从中继日志读取事件,并重做其中的事件从而更新Slave的数据,使其与Master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
经过了上面的简单简介,我们初步了解了什么是主从复制,以及在关系型数据库中数据是如何复制的。在这,我们不由疑问在Redis中又是怎样实现数据复制的呢?别急,我们先来实践一下,先对主从复制得到一个感性认识,再由感性认识升到理性认识去理解一下。So,Let's start doing.
二、在单机上模拟主从复制架构实践2.1 拷贝两个服务到指定磁盘文件夹
(1)将第一篇中下载的Redis服务文件夹复制两份,并给两个文件夹取名为:RedisMasterService与RedisSlaveService;
(2)将两个文件夹拷贝到Windows中指定的文件夹中,我这里统一拷贝到E:下,便于后面的启动测试;
2.2 分别修改Master和Slave的配置文件
(1)修改Master服务的配置文件(redis.conf)
这里,主要修改一下Master服务所绑定的IP地址(即Master服务器的IP地址),我这里由于是在本机进行的,所以直接设置为127.0.0.1即可。通过在redis.conf中搜索”bind”,可以看到默认配置已经有了#bind 127.0.0.1的字符串,我们要做的只是将这句取消注释就可以了。

PS:建议使用类似于EditPlus、Notepad++等专业一点的编辑器打开redis.conf配置文件,这样查找和编辑都比较直观明了。如果这些你都没有,那你可以用Visual Studio打开来编辑(如果你连VS也没有,我只能呵呵了,你用记事本编辑吧,么么嗒)。好吧,我就没有EditPlus和Notepad++,重装了系统就没有装这些编辑器,被你们看穿了。
(2)修改Slave服务的配置文件(redis.conf)
①修改Slave绑定的端口号:这里因为Master和Slave都在一台机器上,因此需要修改端口号以区分两个Redis服务。如果不修改,则默认端口号位6379;修改方法也很简单,搜索”port”关键词,将port 6379改为port 6380即可。注意,这里只要不为6379即可,你可以随便改,6380只是我这里设置的端口号而已。
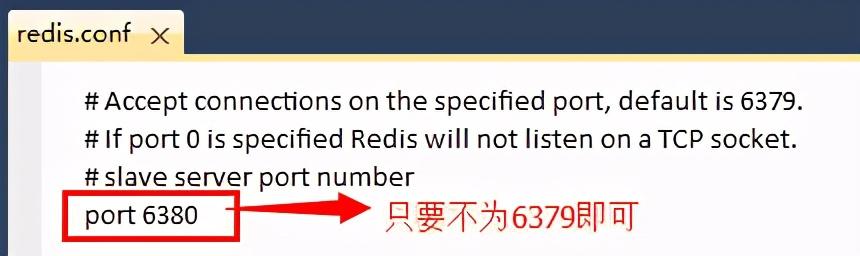
②修改Slave绑定的IP地址,这里和Master一致,都改为bind 127.0.0.1即可;
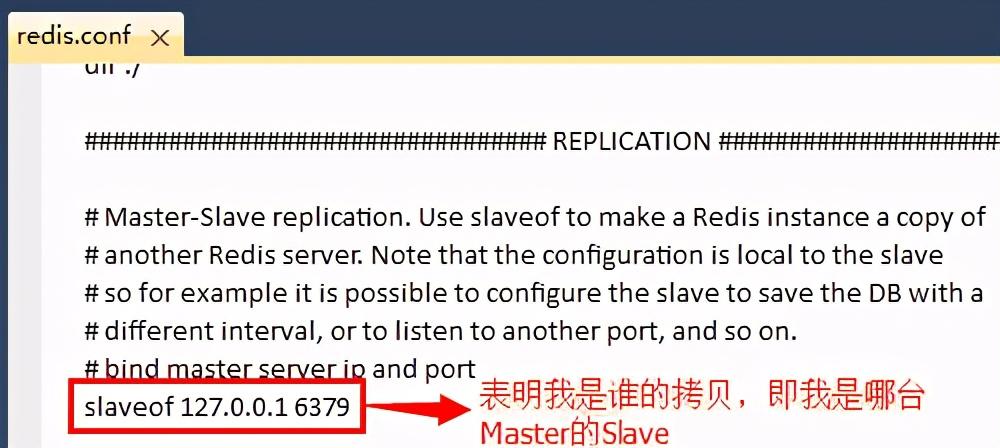
③修改Master与Slave的对应关系配置:搜索”slaveof”关键词,会找到这样一句:# slaveof 。我们要做的就是,取消这句话的注释,并将和改为主服务器的IP地址和端口号,这里我们的Master服务还是本机,因此改为slaveof 127.0.0.1 6379即可。
2.3 分别启动Master和Slave的服务
(1)启动Master的服务:通过cmd跳转到Master文件夹下,使用redis-server.exe redis.conf命令启动Master服务,这里需要指定redis.conf是因为我们刚刚编辑修改了redis.conf,需要重新加载配置文件;
(2)启动Slave的服务:操作步凑同上,也是redis-server.exe redis.conf,注意别忘了加上redis.conf这句;
(3)Slave服务启动完成后,我们可以看到cmd中出现了一些不一样的日志信息。这里,我们来简单的了解一下:
①首先,在Slave服务的命令行中出现如下的日志信息:
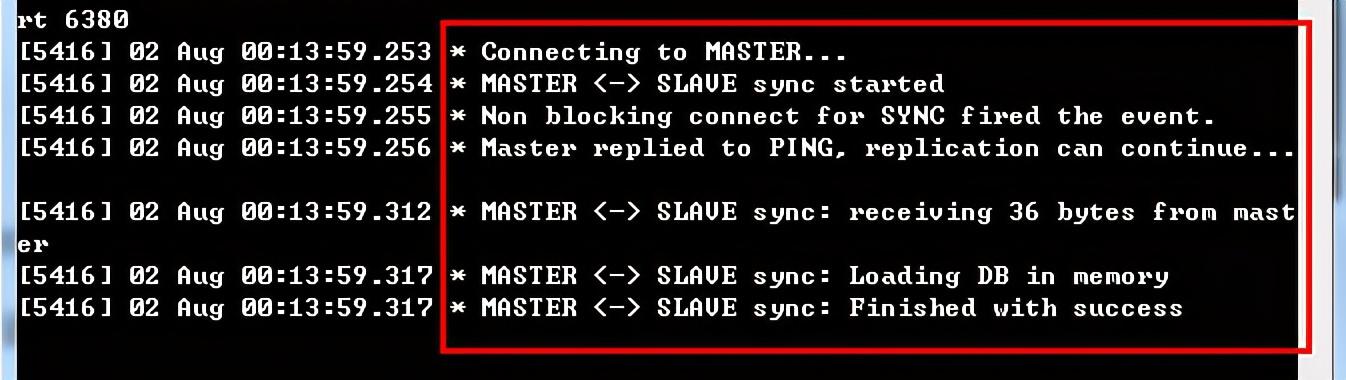
这里,可以看到通过编辑了配置文件后,Slave服务在启动后便会主动地连接Master服务(这里主要是通过发送SYNC命令请求同步连接),中间Master会发一个PING命令来检测Slave的存活状态(存在则继续复制,失效则终止后面步凑),然后等待Master发送回其内存快照文件(这里你先将这个内存快照文件理解为一个数据备份文件或日志)。可以看出,这里Slave已经接受了Master的36 bytes数据,并将数据存储到了内存中,最终成功完成与Master的同步。
②其次,在Master服务的命令行中出现了如下的日志信息:

这里,Master通过检测发现有Slave发送了SYNC命令来判断Master中是否有内存快照(或者更新的内存快照),没有则开始执行内存快照(主要是将),有则等待其结束然后将快照文件发送给Slave。至此,Master端就终止了此次的SYNC通信。而Slave则会将数据快照文件保存到本地,待接收完成后,清空内存表,重新读取Master发来的内存快照文件,形成一个状态的循环。
2.4 在命令行中进行简单数据读写测试
PS:这里主要是通过新开两个cmd窗口来模拟两个客户端来操作Redis
(1)在Master服务中写入一个Key/Value数据对
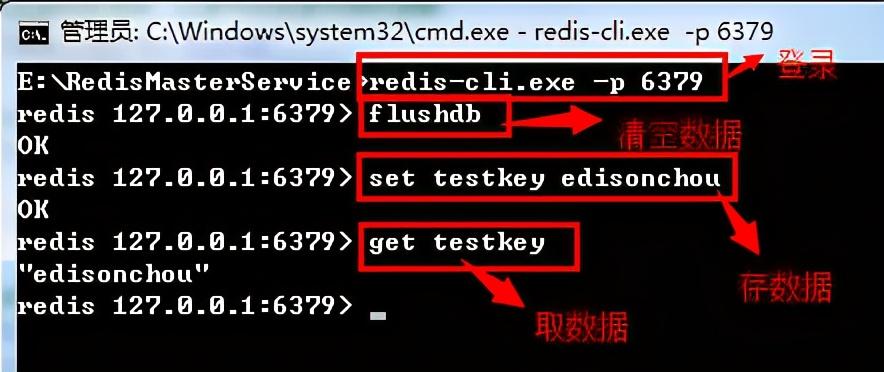
①首先,新开一个cmd,并在cmd中跳转到Master文件夹下,使用redis-cli.exe -p 6379命令进入MasterRedis客户端命令模式
②然后,为了确保测试成功,我们先将当前的Master中的数据清空一下,使用flushdb命令清空已存的所有数据(Redis会定期将数据从内存写入文件中实现数据的持久化)
③最后,通过一个简单的set命令将Key为testkey,Value为edisonchou的键值对数据存入Master中;
(2)在Slave中读取刚刚在Master写入的Key的Value数据
①首先,新开一个cmd,并在cmd中跳转到Slave文件夹下,使用redis-cli.exe -p 6380命令进入SlaveRedis客户端命令模式
②其次,通过一个简单的get命令查询是否存在Key为testkey的数据
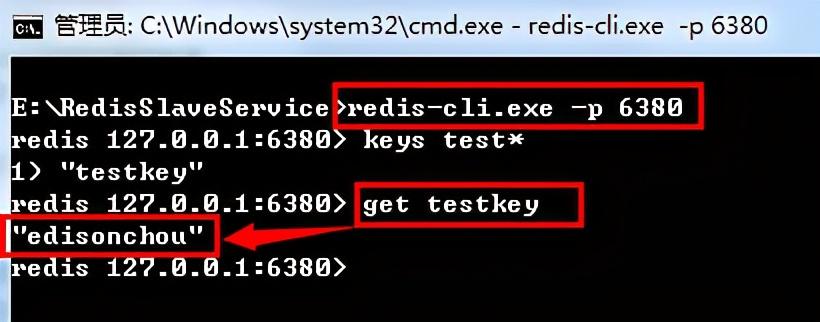
从上图可以看到,我们的Slave成功获取了从Master发来的数据更改,并保存到了自己的数据文件中,使得我们通过访问Slave也能够得到在Master上写入的数据。
(3)再来看看Master和Redis的服务的cmd窗口,是不是又多了一些日志信息:Master将1个changes写入数据快照文件,发送给了Slave。而Slave也将这个change存入自己的数据文件并保存神马快照排名,也就使得{testkey,edisonchou}的这个数据在两个Redis服务中都有了,或者说在Slave中成功复制了Master中的这个key/value对。

2.5 在程序中进行简单数据读写测试
(1)新建一个C#的控制台项目,并在项目文件夹中新建一个Lib文件夹用以存放Redis的.Net驱动(ServiceStack.Redis的dll);
(2)写入以下的代码:
1 public static IRedisClientsManager redisClientManager = new PooledRedisClientManager(new string[]
2 {
3 "127.0.0.1:6379","127.0.0.1:6380"
4 });
5
6 public static IRedisClient redisClient = redisClientManager.GetClient();
7
8 static void Main(string[] args)
9 {
10 if(redisClient != null)
11 {
12 redisClient.Set("UserName","EdisonChou");
13 string userName = redisClient.Get("UserName");
14
15 Console.WriteLine("Hello,My name is {0}.Nice to meet you!", userName);
16 }
17 Console.ReadKey();
18 } 通过调试运行,可以得到以下的结果:
(3)再通过Master和Slave的命令行客户端查看存储情况:
①Master中:get UserName
②Slave中:get UserName
三、回头再看Redis主从复制模型3.1 Redis的两种存储方式
Redis是一个支持持久化的内存数据库,如何实现持久化呢?答案是Redis需要经常将内存中的数据同步到硬盘中来保证持久化。那么,Redis通过什么方式来存储数据呢?
Redis支持两种持久化方式:
(1)SnapsHotting:数据快照,这也是默认的方式。此方式是把数据做一个备份,将数据存储到二进制文件中去(这里可以对比本文最开始介绍的MySQL的复制过程)。这个二进制的文件默认的文件名称为dump.rdb。我们还可以通过配置设置自动做快照持久化的方式,比如:我们可以配置Redis在n秒内如果超过m个key键修改就自动做快照。
但是,快照方式虽然比较完美,但扔存在一定缺陷:由于快照方式是在一定间隔时间做一次的,所以如果Redis意外宕掉的话,就会丢失最后一次快照后的所有修改。因此在完美主义者的推动下,作者增加了aof方式,也就是下面我们所要介绍的方式。
(2)Append-Only File:缩写为aof,意为只增文件。此方式在写入内存数据的同时将操作命令保存到日志文件(默认命名为appendonly.aof),在Redis遇到意外情况后重启时可以通过日志文件恢复数据库状态。但是,正因为如此,在一个并发更改上万的系统中,命令日志是一个非常庞大的数据(日志文件会越来越大),管理维护成本非常高,恢复重建时间也会非常长,这样会导致失去aof高可用性本意(aof的本意其实是数据可靠性及高可用性)。另外更重要的是Redis是一个内存数据结构模型,所有的优势都是建立在对内存复杂数据结构高效的原子操作上,这样就看出aof是一个非常不协调的部分。
刚刚我们说到,Redis默认的存储方式快照方式,那么如果我们要开启aof模式呢?只需要在redis.conf配置文件中将aof模式从no改为yes即可。
3.2 Redis的数据同步流程
首先,Redis的复制功能是完全建立在之前了解的基于内存快照的持久化策略基础上的,也就是说无论你的持久化策略选择的是什么,只要用到了Redis的复制功能,就一定会有内存快照发生。
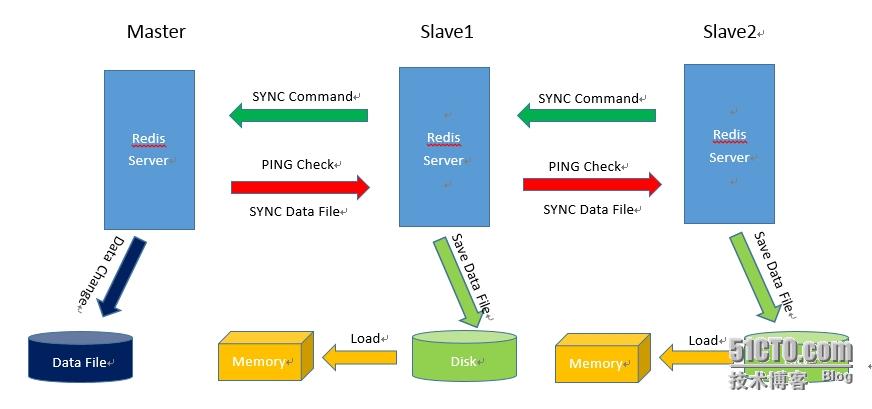
(1)Slave端在配置文件中添加了slave of 的指令,于是Slave启动时读取配置文件并向Master发送SYNC的命令,然后等待Master发送回其内存快照文件;
(2)首先,先说明一下:无论是第一次连接还是重新连接,Master都会启动一个后台进程,将数据快照保存到数据文件(例如:dump.rdb)中,同时Master会记录所有修改数据的命令并缓存在数据文件中。这里紧接第一步,Master接收到Slave发来的SYNC命令后,会首先向Slave发送一个PING命令来检测Slave的存活状态(主要看Slave是否失效,没有失效则继续后续操作,失效了则不继续了)。然后,(当后台进程完成数据缓存操作后)Master就发送数据文件依次地实时发送给Slave。
PS:不管什么原因导致Slave和Master断开重连都会重复以上过程。
(3)Slave接收到Master发来的数据文件之后,会保存到本地,待接收完成后,加载到内存中,这就完成了一次数据复制。之后,Master只要一有数据更新,便会写入数据文件并发送给各个Slave,而Slave也会一直监听Master发来的更新,并重新加载,形成一个数据同步的循环。
(4)若Slave出现故障导致宕机,恢复正常后会自动重新连接,Master收到Slave的连接后,将其完整的数据文件发送给Slave,如果Mater同时收到多个Slave发来的同步请求,Master只会在后台启动一个进程保存数据文件,然后将其发送给所有的Slave,确保Slave正常。但是,在大数据量下,重新获取整个完整的Master快照,一方面Slave恢复的时间会非常慢,另一方面也会给主库带来压力。
四、学习小结
本篇我首先简单介绍了一下主从复制架构的基本概念,然后在Windows上单机模拟实现Redis的主从复制架构并通过数据读写命令进行简单测试并验证数据是否复制成功,最后通过了解Redis的主从复制模型知道了Redis是如何进行数据复制的,从基础理论到基础实践再到基础理论,对于主从复制也不算陌生了(至少混了个脸熟)。

限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688


{kind=link}