
 成为VIP
成为VIP
头图 |CSDN 下载自视觉中国
来源 | 鄙人薛某(ID:gh_4c2f29048530)
对于缓存,大家肯定都不陌生guava缓存,不管是前端还是服务端开发,缓存几乎都是必不可少的优化方式之一。在实际生产环境中,缓存的使用规范也是一直备受重视的,如果使用的不好,很容易就遇到缓存击穿、雪崩等严重异常情景,从而给系统带来难以预料的灾害。
为了避免缓存使用不当带来的损失,我们有必要了解每种异常产生的原因和解决办法,从而做出更好的预防措施。
缓存穿透
而缓存穿透是指缓存和数据库中都没有的数据,这样每次请求都会去查库,不会查缓存,如果同一时间有大量请求进来的话,就会给数据库造成巨大的查询压力,甚至击垮 db 系统。
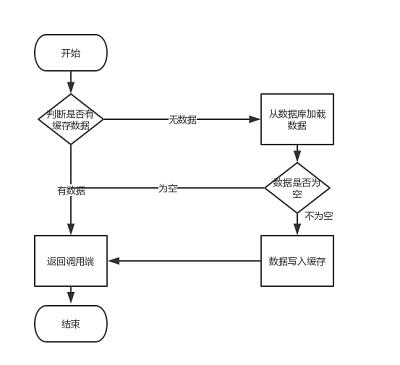
比如说查询 id 为 -1 的商品,这样的 id 在商品表里肯定不存在。如果没做特殊处理的话,攻击者很容易可以让系统奔溃,那我们该如何避免这种情况发生呢?
一般来说,缓存穿透常用的解决方案大概有两种:
1.1 缓存空对象
当缓存和数据都查不到对应 key 的数据时,可以将返回的空对象写到缓存中,这样下次请求该 key 时直接从缓存中查询返回空对象,就不用走 db 了。当然,为了避免存储过多空对象,通常会给空对象设置一个比较短的过期时间,就比如像这样给 key 设置 30秒 的过期时间:
redisTemplate.opsForValue().set(key, null, 30, TimeUnit.SECONDS);这种方法会存在两个问题:
如果有大量的 key 穿透,缓存空对象会占用宝贵的内存空间。
空对象的 key 设置了过期时间,这段时间内可能数据库刚好有了该 key 的数据,从而导致数据不一致的情况。
这种情况下,我们可以用更好的解决方案,也就是布隆过滤器
1.2 Bloom Filter
布隆过滤器(Bloom Filter)是 1970 年由一个叫布隆的小伙子提出的。是一种由一个很长的二进制向量和一系列随机映射函数构成的概率型数据结构,这种数据结构的空间效率非常高,可以用于检索集合中是否存在特定的元素。
设计思想
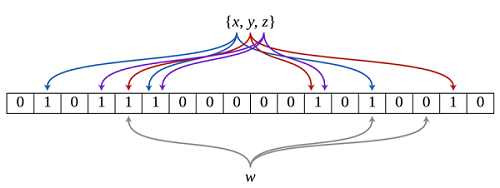
布隆过滤器由一个长度为 m 比特的位数组(bit array)与 k 个哈希函数(hash function)组成的数据结构。原理是当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就大约知道集合中有没有它了,也就是说,如果这些点有任何一个 0 ,则被检元素一定不在;如果都是 1 ,则被检元素很可能在。
至于说为什么都是 1 的情况只是可能存在检索元素,这是因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为 1。
举个例子:下图是一个布隆过滤器,共有 18 个比特位,3 个哈希函数。当查询某个元素 w 时,通过三个哈希函数计算,发现有一个比特位的值为 0,可以肯定认为该元素不在集合中。
优缺点
优点:
缺点:
适用场景
缓存击穿
缓存击穿从字面上看很容易让人跟穿透搞混,这也是很多面试官喜欢埋坑的地方,当然,只要我们对知识点了然于心的话,面试的时候也不会那么被糊弄。
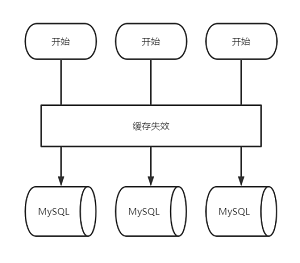
简单来说,缓存击穿是指一个 key 非常热点。在不停的扛着大并发,大并发集中对这一个点进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就好像堤坝突然破了一个口,大量洪水汹涌而入。
当发生缓存击穿的时候,数据库的查询压力会倍增,导致大量的请求阻塞。
解决办法也不难,既然是热点 key,那么说明该 key 会一直被访问,既然如此,我们就不对这个 key 设置失效时间了,如果数据需要更新的话,我们可以后台开启一个异步线程,发现过期的 key 直接重写缓存即可。
当然,这种解决方案只适用于不要求数据严格一致性的情况,因为当后台线程在构建缓存的时候,其他的线程很有可能也在读取数据,这样就会访问到旧数据了。
如果要严格保证数据一致的话,可以用互斥锁
互斥锁
互斥锁就是说,当 key 失效的时候,让一个线程读取数据并构建到缓存中,其他线程就先等待,直到缓存构建完后重新读取缓存即可。
如果是单机系统,用 JDK 本身的同步工具 Synchronized 或 ReentrantLock 就可以实现,但一般来说,都达到防止缓存击穿的流量了谁还搞什么单机系统,肯定是分布式高大上点啊,这种情况我们就可以用分布式锁来做互斥效果。
为了你们能更懂流程,作为暖男的我还是一如既往的给你们准备了伪代码啦:
public String getData(String key){String data = redisTemplate.opsForValue().get(key);if (StringUtils.isNotEmpty(data)){return data;}String lockKey = this.getClass().getName() + ":" + key;RLock lock = redissonClient.getLock(lockKey);try {boolean boo = lock.tryLock(5, 5, TimeUnit.SECONDS);if (!boo) {// 休眠一会儿,然后再请求Thread.sleep(200L);data = getData(key);}// 读取数据库的数据data = getDataByDB(key);if (StringUtils.isNotEmpty(data)){// 把数据构建到缓存中setDataToRedis(key,data);}} catch (InterruptedException e) {// 异常处理,记录日志或者抛异常什么的}finally {if (lock != null && lock.isLocked()){lock.unlock();}}return data;}当然,采用互斥锁的方案也是有缺陷的,当缓存失效的时候,同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。这种情况该如何处理呢?我只能说没什么设计是完美的,你又想数据一致,又想保证吞吐量,哪有那么好的事,为了系统能更加健全,必要的时候牺牲下性能也是可以采取的措施,两者之间怎么取舍要根据实际业务场景来决定,万能的技术方案什么的根本不存在。
缓存雪崩
缓存雪崩也是 key 失效后大量请求打到数据库的异常情况,不过,跟缓存击穿不同的是,缓存击穿因为指一个热点 key 失效导致的情况,而缓存雪崩是指缓存中大批量的数据同时过期,巨大的请求量直接落到 db 层,引起 db 压力过大甚至宕机,这也符合字面上的“雪崩”说法。
解决方案
缓存雪崩的解决方案和击穿的思路一致,可以设置 key 不过期或者互斥锁的方式。
除此之外,因为是预防大面积的 key 同时失效,可以给不同的 key 过期时间加上随机值,让缓存失效的时间点尽量均匀,这样可以保证数据不会在同一时间大面积失效。
redisTemplate.opsForValue().set(Key, value, time + Math.random() * 1000, TimeUnit.SECONDS);同时还可以结合主备缓存策略来让互斥锁的方式更加的可靠。
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
一般来说,上面三种缓存异常场景问的比较多,了解这几种基本就够了,但有些面试官可能喜欢剑走偏锋,进一步延伸其他的异常情景做询问,以防万一,我们也加个菜,介绍下另外两种常见缓存异常。
缓存预热
缓存预热就是系统上线后,先将相关的数据构建到缓存中,这样就可以避免用户请求的时候直接查库。
这部分预热的数据主要取决于访问量和数据量大小。如果数据的访问量不大的话,那么就没必要做预热,都没什么多少请求了,直接按正常的缓存读取流程执行就好。
访问量大的话,也要看数据的大小来做预热措施。
数据量不大的时候,工程启动的时候进行加载缓存动作,这种数据一般可以是电商首页的运营位之类的信息;
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
数据量太大的时候,优先保证热点数据进行提前加载到缓存,并且确保访问期间不能更改缓存,比如用定时器在秒杀活动前30分钟就把商品信息之类的刷新到缓存,同时规定后台运营人员不能在秒杀期间更改商品属性。
缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,类似 HashMap、Guava 这样的工具,一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
当然,这样的操作对于业务是有损害的guava缓存,分布式系统中很容易就出现数据不一致的问题,所以,一般这种情况下,我们都优先保证从运维角度确保缓存服务器的高可用性。比如 Redis 的部署采用集群方式,同时做好备份。总之,尽量避免出现降级的影响。
最后
关于缓存的几大异常处理我们就讲解到这了。虽然每种异常我们都给出了解决的方案,但不是说这玩意直接套上就能用了。现实开发过程中还是要根据实际情况来针对缓存做相应措施,比如用布隆过滤器预防缓存穿透虽然很有效,但并不算特别常用。这年头,防止恶意攻击什么的都是先在运维层面做限制,业务代码层面更多的是对参数和数据做校验。
如果每个使用缓存的地方都要考虑的这么复杂的话,那工作量无疑会更加繁杂,过度设计只会让代码维护起来也麻烦,而且实用性还不一定强,没必要啊。程序员嘛,给自己增添烦恼的事情越少越好,毕竟我们最大的敌人不是996,而是那珍贵的发量啊。
更多精彩推荐 ☞Google回应全球宕机:磁盘满了;摩拜App昨晚正式停止服务;Docker Desktop 3.0.0发布|极客头条
☞开源将走向何方?
☞喜欢 TypeScript 的人,一点都不比 Python 少
☞湘苗培优|从入门到精通
☞百密一疏,防不胜防,细数那些大型数据库建设过程中绕不开的坑
☞被微软称为 “世界的电脑” ,Azure 到底有多牛?
☞程序员才懂的“凡尔赛语录”
点分享 点点赞 点在看 限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



{kind=link}