
 成为VIP
成为VIP
当 MySQL 单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化。
单表优化
除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。而事实上很多时候 MySQL 单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量:
字段
索引
查询 SQL
引擎
目前广泛使用的是 MyISAM 和 InnoDB 两种引擎:
MyISAM
MyISAM 引擎是 MySQL 5.1 及之前版本的默认引擎,它的特点是:
InnoDB
InnoDB 在 MySQL 5.5 后成为默认索引,它的特点是:
总体来讲,MyISAM 适合SELECT密集型的表,而 InnoDB 适合INSERT和UPDATE密集型的表。
系统调优参数
可以使用下面几个工具来做基准测试:
具体的调优参数内容较多,具体可参考官方文档,这里介绍一些比较重要的参数:
升级硬件
Scale up,这个不多说了,根据 MySQL 是 CPU 密集型还是 I/O 密集型,通过提升 CPU 和内存、使用 SSD,都能显著提升 MySQL 性能。
读写分离
也是目前常用的优化,从库读主库写,一般不要采用双主或多主引入很多复杂性,尽量采用文中的其他方案来提高性能。同时目前很多拆分的解决方案同时也兼顾考虑了读写分离。
缓存
缓存可以发生在这些层次:
可以根据实际情况在一个层次或多个层次结合加入缓存。这里重点介绍下服务层的缓存实现,目前主要有两种方式:
表分区
MySQL 在 5.1 版引入的分区是一种简单的水平拆分,用户需要在建表的时候加上分区参数,对应用是透明的无需修改代码。
对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成,实现分区的代码实际上是通过对一组底层表的对象封装,但对 SQL 层来说是一个完全封装底层的黑盒子。MySQL 实现分区的方式也意味着索引也是按照分区的子表定义,没有全局索引。
用户的 SQL 语句是需要针对分区表做优化,SQL 条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区,可以通过EXPLAIN PARTITIONS来查看某条 SQL 语句会落在那些分区上,从而进行 SQL 优化,如下图 5 条记录落在两个分区上:
mysql> explain partitions select count(1) from user_partition where id in (1,2,3,4,5);
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| 1 | SIMPLE | user_partition | p1,p4 | range | PRIMARY | PRIMARY | 8 | NULL | 5 | Using where; Using index |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
1 row in set (0.00 sec)分区的好处是:
分区的限制和缺点:
分区的类型:
分区适合的场景有:
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将热点数据单独放在一个分区,让这个分区的数据能够有机会都缓存在内存中,查询时只访问一个很小的分区表,能够有效使用索引和缓存。
另外 MySQL 有一种早期的简单的分区实现 – 合并表(merge table),限制较多且缺乏优化,不建议使用,应该用新的分区机制来替代。
垂直拆分
垂直分库是根据数据库里面的数据表的相关性进行拆分,比如:一个数据库里面既存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放到用户库、把订单数据放到订单库。垂直分表是对数据表进行垂直拆分的一种方式,常见的是把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联。
比如原始的用户表是:
垂直拆分后是:
垂直拆分的优点是:
缺点是:
水平拆分
概述
水平拆分是通过某种策略将数据分片来存储,分库内分表和分库两部分,每片数据会分散到不同的 MySQL 表或库,达到分布式的效果,能够支持非常大的数据量。前面的表分区本质上也是一种特殊的库内分表。
库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上mysql最大连接数,因此对于减轻 MySQL 服务器的压力来说,并没有太大的作用,大家还是竞争同一个物理机上的 IO、CPU、网络,这个就要通过分库来解决。
前面垂直拆分的用户表如果进行水平拆分,结果是:
实际情况中往往会是垂直拆分和水平拆分的结合,即将 Users_A_M 和 Users_N_Z 再拆成 Users 和 UserExtrasmysql最大连接数,这样一共四张表。
水平拆分的优点是:
缺点是:
分片原则
这里特别强调一下分片规则的选择问题,如果某个表的数据有明显的时间特征,比如订单、交易记录等,则他们通常比较合适用时间范围分片,因为具有时效性的数据,我们往往关注其近期的数据,查询条件中往往带有时间字段进行过滤,比较好的方案是,当前活跃的数据,采用跨度比较短的时间段进行分片,而历史性的数据,则采用比较长的跨度存储。
总体上来说,分片的选择是取决于最频繁的查询 SQL 的条件,因为不带任何 Where 语句的查询 SQL,会遍历所有的分片,性能相对最差,因此这种 SQL 越多,对系统的影响越大,所以我们要尽量避免这种 SQL 的产生。
解决方案
由于水平拆分牵涉的逻辑比较复杂,当前也有了不少比较成熟的解决方案。这些方案分为两大类:客户端架构和代理架构。
客户端架构
通过修改数据访问层,如 JDBC、Data Source、MyBatis,通过配置来管理多个数据源,直连数据库,并在模块内完成数据的分片整合,一般以 Jar 包的方式呈现。
这是一个客户端架构的例子:
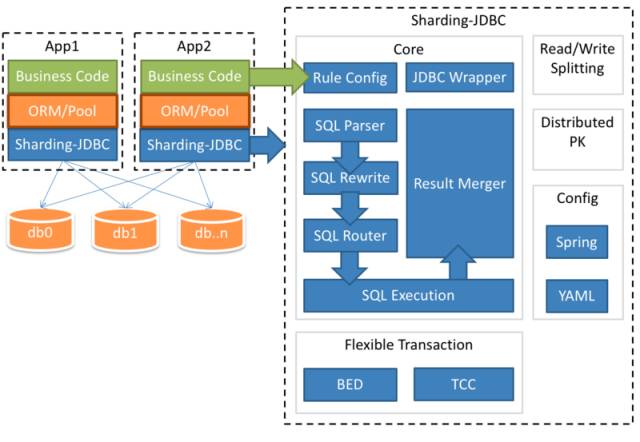
可以看到分片的实现是和应用服务器在一起的,通过修改 Spring JDBC 层来实现。
客户端架构的优点是:
缺点是:
代理架构
通过独立的中间件来统一管理所有数据源和数据分片整合,后端数据库集群对前端应用程序透明,需要独立部署和运维代理组件。
这是一个代理架构的例子:
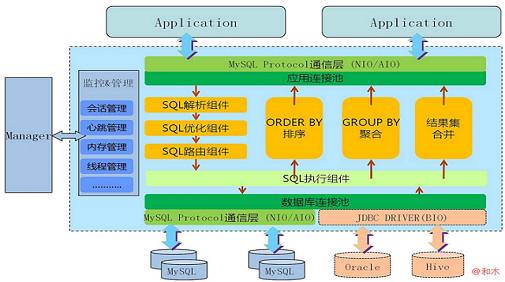
代理组件为了分流和防止单点,一般以集群形式存在,同时可能需要 Zookeeper 之类的服务组件来管理。
代理架构的优点是:
缺点是:
各方案比较
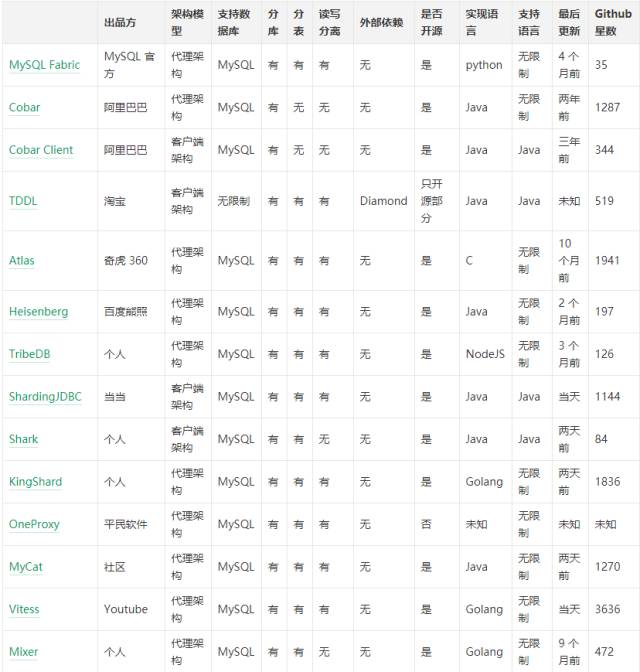
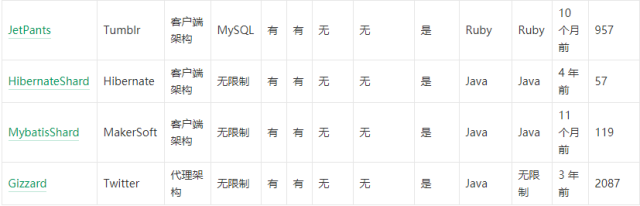
如此多的方案,如何进行选择?可以按以下思路来考虑:
确定是使用代理架构还是客户端架构。中小型规模或是比较简单的场景倾向于选择客户端架构,复杂场景或大规模系统倾向选择代理架构;
具体功能是否满足,比如需要跨节点ORDER BY,那么支持该功能的优先考虑;
不考虑一年内没有更新的产品,说明开发停滞,甚至无人维护和技术支持;
最好按大公司 -> 社区 -> 小公司 -> 个人这样的出品方顺序来选择;
选择口碑较好的,比如 github 星数、使用者数量质量和使用者反馈;
开源的优先,往往项目有特殊需求可能需要改动源代码。
按照上述思路,推荐以下选择:
兼容 MySQL 且可水平扩展的数据库
目前也有一些开源数据库兼容 MySQL 协议,如:
但其工业品质和 MySQL 尚有差距,且需要较大的运维投入,如果想将原始的 MySQL 迁移到可水平扩展的新数据库中,可以考虑一些云数据库:
NoSQL
在 MySQL 上做 Sharding 是一种戴着镣铐的跳舞,事实上很多大表本身对 MySQL 这种 RDBMS 的需求并不大,并不要求 ACID,可以考虑将这些表迁移到 NoSQL,彻底解决水平扩展问题,例如:
限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688



{kind=link}