
 成为VIP
成为VIP

Python部落()组织翻译, 禁止转载
我列出的这些有用的Python代码片段,为我节省了大量的时间,并且我希望他们也能为你节省一些时间。大多数的这些片段出自寻找解决方案,查找博客和StackOverflow解决类似问题的答案。下面所有的代码片段已经在Python 3中测试。
在Python中调用一个外部命令
有时你需要通过shell或命令提示符调用一个外部命令,这在Python中通过使用subprocess模块很容易实现。
只需要运行一条命令:
import subprocess
subprocess.call(['mkdir', 'empty_folder'])
如果想运行一条命令并输出得到的结果:
import subprocess
output = subprocess.check_output(['ls', '-l'])
要说明的是上面的调用是阻塞的。
如果运行shell中内置的命令,如cd或者dir,需要指定标记shell=True:
import subprocess
output = subprocess.call(['cd', '/'], shell=True)
对于更高级的用例json.dump,可以使用 Popen constructor。
Python 3.5引进了一个新的run函数,它的行为与call和check_output很相似。如果你使用的是3.5版本或更高版本,看一看run的文档,里面有一些有用的例子。否则,如果你使用的是Python 3.5以前的版本或者你想保持向后兼容性,上面的call和check_output代码片段是你最安全和最简单的选择。
美观打印
开发时使用pprint模块替代标准的print 函数,可以让shell输出的信息更具可读性。这使得输出到shell上的字典和嵌套对象更易读。
import pprint as pp
animals = [{'animal': 'dog', 'legs': 4, 'breeds': ['Border Collie', 'Pit Bull', 'Huskie']}, {'animal': 'cat', 'legs': 4, 'breeds': ['Siamese', 'Persian', 'Sphynx']}]
pp.pprint(animals, width=1)
width参数指定一行上最大的字符数。设置width为1确保字典打印在单独的行。
按属性进行数据分组
假设你查询一个数据库,并得到如下数据:
data = [
{'animal': 'dog', 'name': 'Roxie', 'age': 5},
{'animal': 'dog', 'name': 'Zeus', 'age': 6},
{'animal': 'dog', 'name': 'Spike', 'age': 9},
{'animal': 'dog', 'name': 'Scooby', 'age': 7},
{'animal': 'cat', 'name': 'Fluffy', 'age': 3},
{'animal': 'cat', 'name': 'Oreo', 'age': 5},
{'animal': 'cat', 'name': 'Bella', 'age': 4}
]
通过动物类型分组得到一个狗的列表和一个猫的列表。幸好,Python的itertools有一个groupby函数可以让你很轻松的完成这些。
from itertools import groupby
data = [
{'animal': 'dog', 'name': 'Roxie', 'age': 5},
{'animal': 'dog', 'name': 'Zeus', 'age': 6},
{'animal': 'dog', 'name': 'Spike', 'age': 9},
{'animal': 'dog', 'name': 'Scooby', 'age': 7},
{'animal': 'cat', 'name': 'Fluffy', 'age': 3},
{'animal': 'cat', 'name': 'Oreo', 'age': 5},
{'animal': 'cat', 'name': 'Bella', 'age': 4}
]
for key, group in groupby(data, lambda x: x['animal']):
for thing in group:
print(thing['name'] + ” is a ” + key)
得到的输出是:
Roxie is a dog
Zeus is a dog
Spike is a dog
Scooby is a dog
Fluffy is a cat
Oreo is a cat
Bella is a cat
groupby()有2个参数:1、我们想要分组的数据,它在本例中是一个字典。2、分组函数:lambda x: x['animal']告诉groupby函数每个字典按动物的类型分组
现在通过列表推导式可以很容易地构建一个狗的列表和一个猫的列表:
from itertools import groupby
import pprint as pp
data = [
{'animal': 'dog', 'name': 'Roxie', 'age': 5},
{'animal': 'dog', 'name': 'Zeus', 'age': 6},
{'animal': 'dog', 'name': 'Spike', 'age': 9},
{'animal': 'dog', 'name': 'Scooby', 'age': 7},
{'animal': 'cat', 'name': 'Fluffy', 'age': 3},
{'animal': 'cat', 'name': 'Oreo', 'age': 5},
{'animal': 'cat', 'name': 'Bella', 'age': 4}
]
grouped_data = {}
for key, group in groupby(data, lambda x: x['animal']):
grouped_data[key] = [thing['name'] for thing in group]
pp.pprint(grouped_data)
最后得到一个按动物类型分组的输出:
{
'cat': [
'Fluffy',
'Oreo',
'Bella'
],
'dog': [
'Roxie',
'Zeus',
'Spike',
'Scooby'
]
}
StackOverflow上这个问题的答案非常有帮助,当我试图找出如何以最Pythonic的方式分组数据时,这篇文章节省了我很多时间。
删除列表中的重复元素
Python中用一行代码快速简单的删除一个列表中的重复元素(不维持顺序):
x = [1, 8, 4, 5, 5, 5, 8, 1, 8]
list(set(x))
这个方法利用了set是一个不同的对象的集合这一事实。然而,set不维持顺序,
因此如果你在乎对象的顺序,使用下面的技术:
from collections import OrderedDict
x = [1, 8, 4, 5, 5, 5, 8, 1, 8]
list(OrderedDict.fromkeys(x))
访问Python的For循环的索引
对于许多人来说这可能是常识,但这也是经常问的。Python的内置enumerate 函数提供索引和值的访问如下:
x = [1, 8, 4, 5, 5, 5, 8, 1, 8]
for index, value in enumerate(x):
print(index, value)
通过指定enumerate函数的start参数改变起始索引:
x = [1, 8, 4, 5, 5, 5, 8, 1, 8]
for index, value in enumerate(x, start=1):
print(index, value)
现在该索引从1到9而不是0到8
并行遍历2个集合
使用内置zip函数同时遍历2个列表,字典json.dump,等。下面是使用zip函数同时遍历2个列表的例子:
a = [1, 2, 3]
b = [4, 5, 6]
for (a_val, b_val) in zip(a, b):
print(a_val, b_val)
将输出:
1 4
2 5
3 6
创建对象的Copy
Python中可以使用通用的copy函数复制一个对象。浅拷贝是通过使用copy.copy调用的:
import copy
new_list = copy.copy(old_list)
深拷贝:
import copy
new_list = copy.deepcopy(old_list)
这个StackOverflow问题对于复制一个列表的各种方法给出了很好的解释。如果你不熟悉浅拷贝和深拷贝之间的差异看一看这个解释。
浮点除法
通过将分子或分母转换为float类型,可以确保浮点除法:
answer = a/float(b)
字符串和日期相互转换
一个常见的任务是将一个字符串转换为一个datetime对象。使用strptime 函数这将很容易做到:
from datetime import datetime
date_obj = datetime.strptime('May 29 2015 2:45PM', '%B %d %Y %I:%M%p')
它的逆操作是转换一个datetime对象为一个格式化的字符串,对datetime对象使用strftime函数:
from datetime import datetime
date_obj = datetime.now()
date_string = date_obj.strftime('%B %d %Y %I:%M%p')
有关格式化代码的列表和他们的用途,查看官方文档
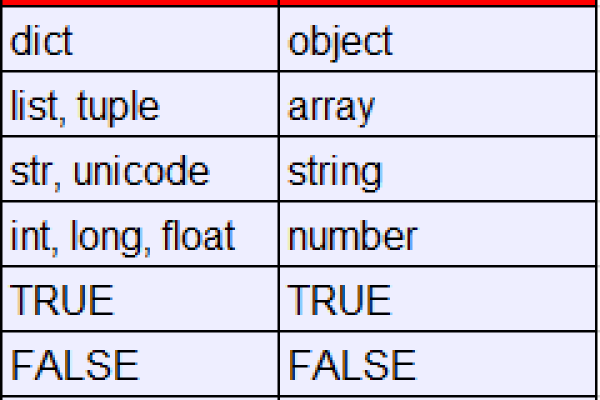
解析JSON文件并写一个对象到JSON文件中
使用load函数可以解析JSON文件并构建一个Python对象。假定有一个叫做data.json的文件包括以下数据:
{
“dog”: {
“lives”: 1,
“breeds”: [
“Border Collie”,
“Pit Bull”,
“Huskie”
]
},
“cat”: {
“lives”: 9,
“breeds”: [
“Siamese”,
“Persian”,
“Sphynx”
]
}
}
import json
with open('data.json') as input_file:
data = json.load(input_file)
现在data是一个对象,你可以操作它像任何Python对象一样:
print(data['cat']['lives'])
output: 9
可以使用dump函数,将Python中的字典写入JSON文件中:
import json
data = {'dog': {'legs': 4, 'breeds': ['Border Collie', 'Pit Bull', 'Huskie']}, 'cat': {'legs': 4, 'breeds': ['Siamese', 'Persian', 'Sphynx']}}
with open('data.json', 'w') as output_file:
json.dump(data, output_file, indent=4)
缩进参数美观打印JSON字符串以便输出更容易阅读。在这种情况下,我们指定缩进4个空格。
英文原文:
译者: 毛茸茸的向日葵
长按, 识别图中二维码
关注”Python程序员”
限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688



{kind=link}