
 成为VIP
成为VIP
这是 Kotlin 团队的一个建议:避免将解构声明和数据类一起使用,如果以后往数据类添加新的属性,很容易破坏代码的结构。我们一起来思考一下,为什么 Kotlin 官方会这么说,我先来看一个例子: 数据类和解构声明的使用。
<pre class="code-snippet__js" data-lang="kotlin“>// 数据类data class People( val name: String, val city: String)fun main(args: Array<String>) { // 编译测试 printlnPeople(People("dhl", "beijing"))}fun printlnPeople(people: People) { // 解构声明,获取 name 和 city 并将其输出 val (name, city) = people println("name: ${name}") println("city: ${city}")}
输出结果如下所示:
name: dhlcity: beijing
随着需求的变更,需要给数据类 People 添加一个新的属性 age。
// 数据类,增加了 agedata class People(val name: String,val age: Int,val city: String)fun main(args: Array<String>) {// 编译测试printlnPeople(People("dhl", 80, "beijing"))}
此时没有更改解构声明,也不会有任何错误,编译输出结果如下所示:
name: dhlcity: 80
得到的结果并不是我们期望的,此时我们不得不更改解构声明的地方,如果代码中有多处用到了解构声明,因为增加了新的属性,就要去更改所有使用解构声明的地方,这明显是不合理的,很容易破坏代码的结构,所以一定要避免将解构声明和数据类一起使用。当我们使用不规范的时候,编译器也会给出警告,如下图所示。

文件的扩展方法
Kotlin 提供了很多文件扩展方法 Extensions for java.io.Reade:forEachLine、 readLines、readText、useLines 等等,帮助我们简化文件的操作,而且使用完成之后,它们会自动关闭,例如 useLines 方法:
File("dhl.txt").useLines { line ->println(line)}
useLines 是 File 的扩展方法,调用 useLines 会返回一个文件中所有行的 Sequence,当文件内容读取完毕之后,它会自动关闭,其源码如下。
public inline fun File.useLines(charset: Charset = Charsets.UTF_8, block: (Sequence<String>) -> T): T =bufferedReader(charset).use { block(it.lineSequence()) }
那它是如何在读取完毕自动关闭的呢,核心在 use 方法里面,在 useLines 方法内部调用了 use 方法,use 方法也是一个扩展方法,源码如下所示。
public inline fun T.use(block: (T) -> R): R {var exception: Throwable? = nulltry {return block(this)} catch (e: Throwable) {exception = ethrow e} finally {when {apiVersionIsAtLeast(1, 1, 0) -> this.closeFinally(exception)this == null -> {}exception == null -> close()else ->try {close()} catch (closeException: Throwable) {// cause.addSuppressed(closeException) // ignored here}}}}
其实很简单,调用 try…catch…finally 最后在 finally 内部进行 close。其实我们也可以根据源码实现一个通用的异常捕获方法。
inline fun T.dowithTry(block: (T) -> R) {try {block(this)} catch (e: Throwable) {e.printStackTrace()}}// 使用方式dowithTry {// 添加会出现异常的代码, 例如val result = 1 / 0}
当然这只是一个非常简单的异常捕获方法,在实际项目中还有很多需要去处理的,比如说异常信息需不需要返回给调用者等等。
在上文中提到了调用 useLines 方法返回一个文件中所有行的 Sequence,为什么 Kotlin 会返回 Sequence,而不返回 Iterator?
Sequence 和 Iterator 不同之处
为什么 Kotlin 会返回 Sequence,而不返回 Iterator?其实这个核心原因由于 Sequence 和 Iterator 实现不同导致内存和性能有很大的差异。
接下来我们围绕这两个方面来分析它们的性能,Sequences (序列) 和 Iterator (迭代器) 都是一个比较大的概念,本文的目的不是去分析它们,所以在这里不会去详细分析 Sequence 和 Iterator,只会围绕着内存和性能两个方面去分析它们的区别,让我们有一个直观的印象。更多信息可以查看国外一位大神写的文章。
Sequence 和 Iterator 从代码结构上来看,它们非常的相似如下所示:
interface Iterable<out T> {operator fun iterator(): Iterator}interface Sequence<out T> {operator fun iterator(): Iterator}
除了代码结构之外,Sequences (序列) 和 Iterator (迭代器) 它们的实现完全不一样。
Sequences (序列)
Sequences 是属于懒加载操作类型,在 Sequences 处理过程中,每一个中间操作不会进行任何计算,它们只会返回一个新的 Sequence,经过一系列中间操作之后,会在末端操作 toList 或 count 等等方法中进行最终的求值运算,如下图所示。
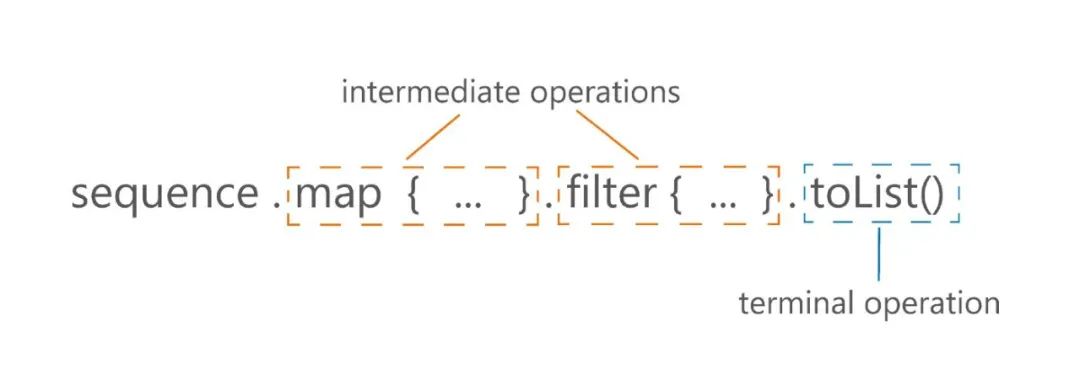
在 Sequences 处理过程中,会对单个元素进行一系列操作,然后在对下一个元素进行一系列操作,直到所有元素处理完毕。
val data = (1..3).asSequence().filter { print("F$it, "); it % 2 == 1 }.map { print("M$it, "); it * 2 }.forEach { print("E$it, ") }println(data)// 输出 F1, M1, E2, F2, F3, M3, E6
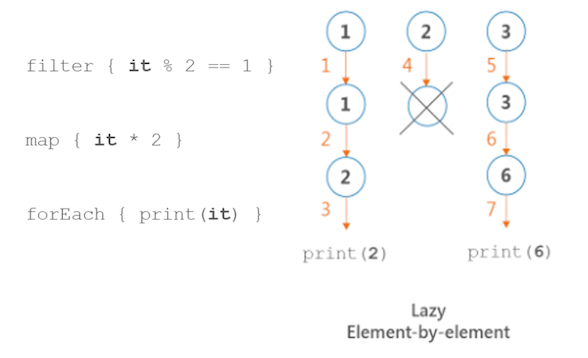
如上所示:在 Sequences 处理过程中,对 1 进行一系列操作输出 F1, M1, E2, 然后对 2 进行一系列操作,依次类推,直到所有元素处理完毕javasubstring截取字符串用法,输出结果为 F1, M1, E2, F2, F3, M3, E6。
在 Sequences 处理过程中,每一个中间操作 (map、filter 等等) 不进行任何计算,只有在末端操作 (toList、count、forEach 等等方法) 进行求值运算,如何区分是中间操作还是末端操作,看方法的返回类型,中间操作返回的是Sequence,末端操作返回的是一个具体的类型 (List、int、Unit 等等) 源码如下所示。
// 中间操作 map ,返回的是 Sequencepublic fun Sequence.map(transform: (T) -> R): Sequence {return TransformingSequence(this, transform)}// 末端操作 toList 返回的是一个具体的类型(List)public fun Sequence.toList(): List {return this.toMutableList().optimizeReadOnlyList()}// 末端操作 forEachIndexed 返回的是一个具体的类型(Unit)public inline fun Sequence.forEachIndexed(action: (index: Int, T) -> Unit): Unit {var index = 0for (item in this) action(checkIndexOverflow(index++), item)}
Iterator (迭代器)
在 Iterator 处理过程中,每一次的操作都是对整个数据进行操作,需要开辟新的内存来存储中间结果,将结果传递给下一个操作,代码如下所示:
val data = (1..3).asIterable().filter { print("F$it, "); it % 2 == 1 }.map { print("M$it, "); it * 2 }.forEach { print("E$it, ") }println(data)// 输出 F1, F2, F3, M1, M3, E2, E6
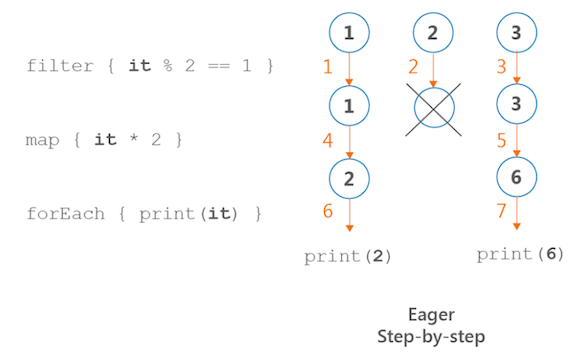
如上所示:在 Iterator 处理过程中,调用 filter 方法对整个数据进行操作输出 F1, F2, F3,将结果存储到 List 中, 然后将结果传递给下一个操作 (map)输出 M1, M3 将新的结果在存储的 List 中, 直到所有操作处理完毕。
// 每次操作都会开辟一块新的空间,存储计算的结果public inline fun Iterable.filter(predicate: (T) -> Boolean): List {return filterTo(ArrayList(), predicate)}// 每次操作都会开辟一块新的空间,存储计算的结果public inline fun Iterable.map(transform: (T) -> R): List {return mapTo(ArrayList(collectionSizeOrDefault(10)), transform)}
对于每次操作都会开辟一块新的空间,存储计算的结果,这是对内存极大的浪费,我们往往只关心最后的结果,而不是中间的过程。
了解完 Sequences 和 Iterator 不同之处,接下来我们从性能和内存两个方面来分析 Sequences 和 Iterator。
Sequences 和 Iterator 性能对比
分别使用 Sequences 和 Iterator 调用它们各自的 filter、map 方法,处理相同的数据的情况下,比较它们的执行时间。
使用 Sequences:
val time = measureTimeMillis {(1..10000000 * 10).asSequence().filter { it % 2 == 1 }.map { it * 2 }.count()}println(time) // 1197
使用 Iterator:
val time2 = measureTimeMillis {(1..10000000 * 10).asIterable().filter { it % 2 == 1 }.map { it * 2 }.count()}println(time2) // 23641
Sequences 和 Iterator 处理时间如下所示:
Sequences
Iterator
1197
23641
这个结果是很让人吃惊的,Sequences 比 Iterator 快 19 倍,如果数据量越大,它们的时间差距会越来越大,当我们在读取文件的时候,可能会进行一系列的数据操作 drop、filter 等等,所以 Kotlin 库函数 useLines 等等方法会返回 Sequences,因为它们更加的高效。
Sequences 和 Iterator 内存对比
这里使用了 Prefer Sequence for big collections with more than one processing step 文章的一个例子。
有 1.53 GB 犯罪分子的数据存储在文件中,从文件中找出有多少犯罪分子携带大麻,分别使用 Sequences 和 Iterator,我们先来看一下如果使用 Iterator 处理会怎么样 (这里调用 readLines 函返回 List)
File("ChicagoCrimes.csv").readLines().drop(1) // Drop descriptions of the columns.mapNotNull { it.split(",").getOrNull(6) }// Find description.filter { "CANNABIS" in it }.count().let(::println)
运行完之后,您将会得到一个意想不到的结果 OutOfMemoryError
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space调用 readLines 函返回一个集合,有 3 个中间操作,每一个中间操作都需要一块空间存储 1.53 GB 的数据,它们需要占用超过 4.59 GB 的空间,每次操作都开辟了一块新的空间,这是对内存巨大浪费。如果我们使用序列 Sequences 会怎么样呢? (调用 useLines 方法返回的是一个 Sequences)。
File("ChicagoCrimes.csv").useLines { lines ->// The type of `lines` is Sequencelines.drop(1) // Drop descriptions of the columns.mapNotNull { it.split(",").getOrNull(6) }// Find description.filter { "CANNABIS" in it }.count().let { println(it) } // 318185
没有出现 OutOfMemoryError 异常,共耗时 8.3s,由此可见对于文件操作使用序列不仅能提高性能,还能减少内存的使用,从性能和内存这两方面也解释了为什么 Kotlin 库的扩展方法 useLines 等等,读取文件的时候使用 Sequences 而不使用 Iterator。
便捷的 joinToString 方法的使用
joinToString 方法提供了一组丰富的可选择项 (分隔符,前缀,后缀,数量限制等等) 可用于将可迭代对象转换为字符串。
val data = listOf("Java", "Kotlin", "C++", "Python").joinToString(separator = " | ",prefix = "{",postfix = "}") {it.toUpperCase()}println(data) // {JAVA | KOTLIN | C++ | PYTHON}
这是很常见的用法,将集合转换成字符串,高效利用便捷的 joinToString 方法,开发的时候事半功倍javasubstring截取字符串用法,既然可以添加前缀,后缀,那么可以移除它们吗? 可以的,Kotlin 库函数提供了一些方法,帮助我们实现,如下代码所示。
var data = "**hi dhl**"// 移除前缀println(data.removePrefix("**")) // hi dhl**// 移除后缀println(data.removeSuffix("**")) // **hi dhl// 移除前缀和后缀println(data.removeSurrounding("**")) // hi dhl// 返回第一次出现分隔符后的字符串println(data.substringAfter("**")) // hi dhl**// 如果没有找到,返回原始字符串println(data.substringAfter("--")) // **hi dhl**// 如果没有找到,返回默认字符串 "no match"println(data.substringAfter("--","no match")) // no matchdata = "{JAVA | KOTLIN | C++ | PYTHON}"// 移除前缀和后缀println(data.removeSurrounding("{", "}")) // JAVA | KOTLIN | C++ | PYTHON
有了这些 Kotlin 库函数,我们就不需要在做 startsWith() 和 endsWith() 的检查了,如果让我们自己来实现上面的功能,我们需要花多少行代码去实现呢,一起来看一下 Kotlin 源码是如何实现的,上面的操作符最终都会调用以下代码,进行字符串的检查和截取。
public String substring(int beginIndex, int endIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}if (endIndex > value.length) {throw new StringIndexOutOfBoundsException(endIndex);}int subLen = endIndex - beginIndex;if (subLen < 0) {throw new StringIndexOutOfBoundsException(subLen);}return ((beginIndex == 0) && (endIndex == value.length)) ? this: new String(value, beginIndex, subLen);}
参考源码的实现,如果以后遇到类似的需求,但是 Kotlin 库函数又无法满足我们,我们可以以源码为基础进行扩展。
全文到这里就结束了,Kotlin 的强大不止于此,后面还会分享更多的技巧,在 Kotlin 的道路上还有很多实用的技巧等着我们一起来探索。
“开发者说·DTalk” 面向中国开发者们征集 Google

移动应用 (apps & games)相关的产品/技术内容。欢迎大家前来分享您对移动应用的行业洞察或见解、移动开发过程中的心得或新发现、以及应用出海的实战经验总结和相关产品的使用反馈等。我们由衷地希望可以给这些出众的中国开发者们提供更好展现自己、充分发挥自己特长的平台。我们将通过大家的技术内容着重选出优秀案例进行谷歌开发技术专家 (GDE)的推荐。
限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688




{kind=link}