
 成为VIP
成为VIP

一、为什么从开发转测试
笔者从2019年5月开始从一名java开发女程序猿正式转为测试开发工程师,原因除了机缘凑巧之外,当然是因为这个行业对测试工程师的要求已经越来越高,简单做些UI脚本录制和回放的自动化,参考度娘写出框架demo却不知道问题出在哪里的测试人员,已经不能满足企业快速迭代产品,保证产品质量的需求。当一个产品越来越庞大、用例越来越多,用例如何设置、脚本如何规划、代码结构如何优化,当需求变动时又如何做到高可维护、高健壮性的问题会接踵而来。所以,一名优秀的测试开发工程师是必须具备优秀的代码能力,甚至知识面是需要比普通的开发人员更广的,比如他需要熟悉自动化测试、服务器部署、网络架构、软件性能、软件安全等等方面的知识。所以开发工程师转测试之后可做的内容非常的多,测试这块领域也需要更多有开发背景的人员加入。
二、前言
背景唠嗑完,我们来说说面试题,由于是开发转测试,首先开发的进阶基础知识是必须要掌握的,面试官也肯定会问(说不定直接是开发组的人面的),接着会问一些功能测试的知识点,但是一般不会多,然后是比较重要的自动化测试部分,做自动化测试框架有很多,每个公司用的也不一样,如果没用过面试官说的,就说自己用过那套的逻辑就好。如果没有在工作中实践过,非常有必要的告诉大家,在面试之前也一定要多百度熟悉多动手写demo,不要让面试官问的工具和术语你都没听说过,那么还没开始就结束了的面试只会剩下尬聊(哭晕)。最后前面聊得愉快的话,面试官一般还会继续考察你的其他能力,比如性能、安全、Linux、数据库、软件架构等。下述内容为大家准备了每个知识点比较常见的面试题list转json,大家可以参考并且发散准备,最后记得准备必问题目:为什么从开发转测试?参考我第一章的答案?
三、开发基础面试题

自动化常用的语言是java和python,参考面试题:
(1)JAVA知识
Q1:List、Set、Map 之间的区别
List 是一个有序并且允许元素重复的集合,它的底层数据结构是数组,数组的优缺点都很明显,就是查询速度很快,但是要做数据移动,比如增加、删除速度就会很慢。
Set 是一个无序且不允许元素重复的集合,它的底层数据结构是哈希表,它的优缺点是跟数组完全相反的,既查询速度慢,但是增加、删速度很快。
Map也是集合的一部分,它最大的特点是key-value形的,并且key不能重复出现,但是value可以重复出现,这对我们某些业务,如用户重复处理能起到重要作用。
Q2:ArrayList 与 LinkedList 的区别?
ArrrayList说白了就是个数组,所以自然也是有数据的优缺点的,比如支持随机访问,查询速度快。而LinkedList 的底层数据结构是链表,所以是不支持随机访问的,在代码中用下标访问一个元素时,ArrayList 的time complexity是 O(1),而 LinkedList 是O(n)。
Q3:Hashtable 与 HashMap 有什么不同之处?
Hashtable 是过时了的遗留下来的类,后面新增的是HashMap。Hashtable 的方法是同步的,所以时间上比较慢,但HashMap 没有同步策略,虽然时间更快了但是也导致它另外一个问题:HashMap是线程不安全的。因为是异步的,在线程并发时可能会导致数据错乱。
Q4:Java 中 ++ 操作符是线程安全的吗?
当然不是线程安全的操作,因为这个过程涉及到多个指令,比如先读取变量值,然后进行增加操作,最后存储回内存,整个过程可能会出现多个线程交差。所以说它不是线程安全的。
Q5:int 和 Integer 哪个会占用更多的内存?
由于Integer 是一个对象,不仅需要存储指向对象的指针,还要存储对象值,所以会占用更多的内存。但是 int 是八种数据类型之一,不需要实例化才能使用,所以占用的空间更少一些。
Q6:Java 中 sleep 方法和 wait 方法的区别?
这两个方法是继承自不同的类的,所以虽然都可以用来暂停当前运行的线程,但sleep() 只是短暂停顿,并不会释放锁,而 wait() 是条件等待,使用了该方法之后,还要释放锁,不然其他等待的线程就不能在满足条件时获取到该锁。而且sleep必须捕获异常的,但wait不需要捕获异常
Q7:解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一个进程,回收无效对象的内存用于将来的分配。
(2)Python知识
Q1:python的八大基本数据类型是?
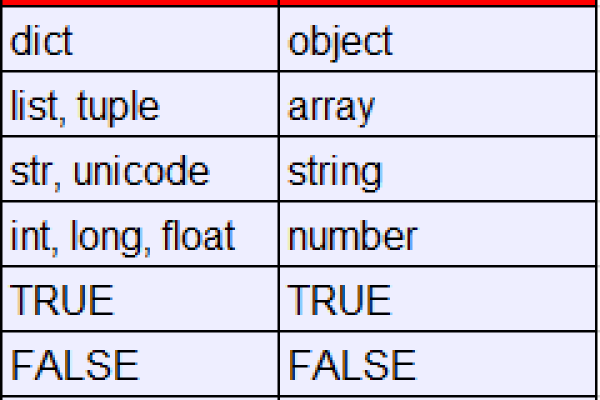
int、str、float、list、bool、tuple元组、dict字典、set集合
Q2:python中可变数据类型和不可变数据类型有哪些?
不可变数据类型:数值型、字符串string、元组tuple,这类数据类型改变了变量的值相当于是新建了一个对象,也就是如果值是是相同,那么只用一个内存地址保存
可变数据类型:列表list、字典dict:允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化
Q3:python字典和json字符串相互转化方法是?
字典转json使用:json.dumps()
json转字典使用:json.loads()
Q4:Python中@staticmethod和@classmethod的区别
首先说一下什么是普通方法,普通方法需要传递参数,类调用的时默认会将类的实例对象传进去。
@staticmethod装饰的静态方法与普通函数相同:实例和类均可调用,但是不需要传递默认的参数进去
@classmethod装饰的类方法:也需要参数,使用时需要将调用的类传进去
Q5:什么是装饰器?
装饰器的本质是一个闭包函数,实现的功能是在不修改原函数及调用方式的情况下对原函数进行功能扩展的,是开放封闭原则的典型代表,我们在业务中有编程场景可以用上装饰器,比如用户登陆后的权限校验、执行函数前的预备处理、执行后的功能清理、以及更高级的事务处理等等。
Q6:python中常见的异常举例
Exception 所有异常类的基类
AssertionError assert语句失败
FileNotfoundError 文件打开失败
AttributeError 试图访问对象没有属性
Q7:Python是如何进行内存管理的?
Python一个高效语言的原因之一是因为它有非常完善的内存管理机制,在python中万物皆对象list转json,所以围绕对象的内存管理是整个的核心。
第一:对象的引用计数机制,python是使用引用计数来保持追踪内存中的对象。
第二:垃圾回收机制,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉,保证对象可回收。
第三:内存池机,Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统制
(3)数据库知识
Q1:数据表project有code字段,其中code中的编码名有重复,如何消除重复行?
select distinct code from project
Q2:什么是内链接、左链接、右链接、全链接?
(1)INNER JOIN产生的结果集中,是左和右的交集
(2)LEFT JOIN返回左表的全部行和右表满足ON条件的行,其他null替代
(3)RIGHT JOIN返回右表的全部行和左表满足ON条件的行,其他null替代 (4)FULL JOIN 会从左表 和右表 那里返回所有的行,如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替。这个问题基本是问数据库问题必问的,大家还可以深入准备下哪些业务场景用到哪种链接。
Q3:某个字段被建立索引后,数据的什么操作会使用到该索引?
(1)对建立了索引的字段做where条件查询时
(2)多表做join操作时会使用索引
(3)对建立了索引的字段做min()或max()时
(4)对建立了索引的字段做sort排序操作时
其中我们用索引最多的时候在查询场景,但同时索引查询也会增加内存消耗,所以索引查询该如何优化是一个更大的问题,此类问题也是数据库常见面试题之一,有兴趣的小伙伴可以自行查阅资料。
限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688


{kind=link}