
 成为VIP
成为VIP

温馨提示,动图已压缩,流量党放心查看。CPU方面内容不多,我们顺便学点命令。本篇是《荒岛余生》系列第二篇,垂直观测CPU。其余参见:
如何做一个CPU
cpu是芯片的一种,我们以汉芯为例,看一下制作七步曲。
➊ 提纯精度11个9的硅片(99.999999999%)
➋ 生成晶圆
➌ 使用光刻机加工晶圆
➍ 使用刻蚀机沟槽
➎ 完成P型半导体制作
➏ 使用200号的粗砂纸抹掉原标志
➐ 涂上新标志
bingo,完工!
虽然CPU很小,但生产它的设备可不简单。如下图,就是一台重十几吨,占地上百平米,全世界都当宝贝的光刻机!

你我就这样饱受科技的恩泽,有时间探讨在中央处理器上发生的故事了。
找到占用CPU最高的线程
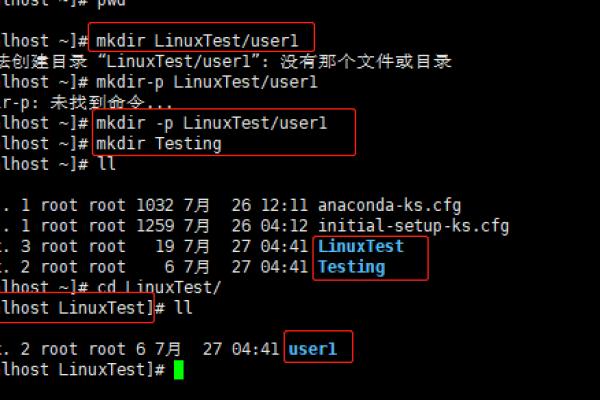
接下来看一个实际的例子。公司有点穷,所以机器上混合部署了多个java应用,突然有一天,CPU炸了,我们要找到是谁引起的。这个谁不是进程,而是线程,离真相最近的那个。
传统做法
通常的做法是:
➊ 在命令行输入top,然后shift+p查看占用CPU最高的进程,记下进程号
➋ 在命令行输入top -Hp 进程号,查看占用CPU最高的线程
➌ 使用printf 0x%x 线程号,得到其16进制线程号
➍ 使用jstack 进程号得到java执行栈,然后grep16进制找到相应的信息
录个屏先
拔萝卜带泥
但我想通过另外一种方式来实现这个功能(最多样化),顺便学几个其他常用的命令。
ps -eo %cpu,pid |sort -n -k1 -r | head -n 1 | awk '{print $2}' |xargs top -b -n1 -Hp | grep COMMAND -A1 | tail -n 1 | awk '{print $1}' | xargs printf 0x%x这一行Shell的意思是,找到使用CPU最高的进程之使用CPU最高的线程的16进制号。
这么长的命令,是不是晕了?别怕,我们一点点来。通常情况下,练习熟练了命令中出现的这几个,就能够应对50%的常用工作了。Come on,上图。
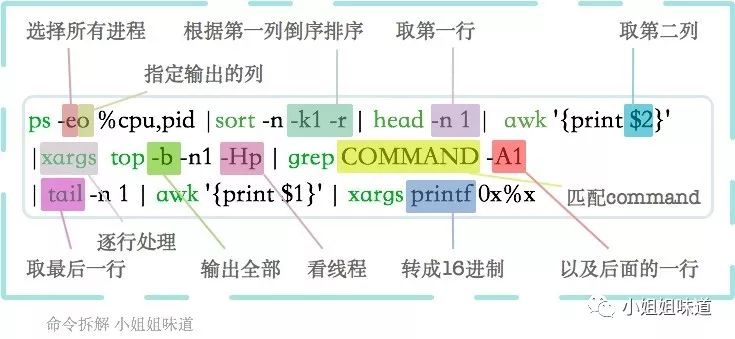
接下来,试着写一下脚本吧。
有哪些查看CPU的命令top
其实从上面命令就可以瞧出来,top和ps的命令是互通的,只不过表现形式不同,我们直接拿top来说。按数字1就可以显示每核CPU的使用情况。基本上都是些单词的缩写,看几遍就忘不掉了。比如 :
us ==> user CPU time先记住这些判断准则,我们在示例中再聊:
➊ 如果load超过了cpu核数,则负载过高
➋ 如果wa过高,可初步判断I/O有问题
➌ sy,si,hi,st,任何一个超过5%,都有问题
➍ 进程状态长时处于D、Z、T状态,提高注意度
➎ cpu不均衡,判断亲和性和优先级问题
vmstat
vmstat 以另一种形式来展示一些信息。如图:

除了关注类似top的一些指标,还有:
➊ b 置于等待队列(等待资源、等待输入/输出)的内核线程数目。数字过大则cpu太忙。
➋ cs 如果频繁的进行上下文切换,则考虑是否是线程数开的过多
➌ si/so 显示了交换分区的现状,有时候会造成cpu问题,一并关注
sar
是目前Linux上最为全面的系统性能分析工具之一,但可能没有预装。在centos上使用以下命令即可安装。
yum install sysstat -ysar主要的好处是可以看到历史,显示友好,可以对结果进行二次处理。sar还有图形化工具,执行sar -A即可获得所有数据。
https://github.com/vlsi/ksar针对于CPU方面,我们关注:
➊ sar -u 默认
➋ sar -P ALL 每颗cpu的使用状态信息
➌ sar -q cpu队列的长度,runq-sz>cpu count就表明有瓶颈了
➍ sar -w 每秒上下文交换
可以瞧见,关注的也就那几个点而已。
mpstat
还有pidstat,包括彩色的dstat,功能都差不多, 用熟一个就ok了。
数据从何而来
那么数据从何而来?
/proc目录是一个虚拟目录,存储的是当前内核的一系列特殊文件,你不仅能查看一些状态,甚至能修改一些值来改变系统的行为。
比如top的load (使用uptime命令得到同样的结果)。读取的就是
/proc/loadavg 文件
而每核cpu的信息,读取
/proc/stat文件
这些命令,是对/proc目录中一系列信息的解析和友好的展示,这些值linux查看cpu核数,Linux内核都算好了躺在那呢。

(图片来源网络)
创建这个目录的人真是天才!
几个例子
CPU过高是表象。除了系统确实负载已经到了极限,其他的,都是由其他原因引起的,比如I/O;比如设备。这些我们放在其他章节进行讨论。
GC引起的CPU过高
接着我们最开始的例子来。通过查看jstack找到相应的16进制进程,结果发现是GC线程。
"VM Thread" prio=10 tid=0x00007f06d8089000 nid=0x58c7 runnable
"GC task thread#0 (ParallelGC)" prio=10 tid=0x00007f06d801b800 nid=0x58d7 runnable这种情况,一般都是JVM内存不够用了,疯狂GC,可能是socket/线程忘了关闭了,也可能是大对象没有回收。这种情况只能通过重启来解决了,记得重启之前,使用jmap dump一下堆栈哦。当然,你可能会得到jdk版本的问题。
st%占比过高
st过高一般是物理CPU资源不足所致,也就是只发生在虚拟机上。
如果你买的虚拟机st一直很高,那你的服务提供商可能在超卖,挤占你的资源。不信双11的时候看下你的虚拟机?
网卡导致单cpu过高
业务方几台kafka,cpu使用处于正常水平,才10%左右,但有一核cpu,负载特别的高,si奇高。
mpstat -I SUM -P ALL 查看cpu使用情况,cpu0的中断确实比较多。
20:15:18 CPU intr/s
20:15:23 all 34234.20
20:15:23 0 9566.20
20:15:23 1 0.00网卡需要cpu服务时,都会抛出一个中断,中断告诉cpu发生了什么事情,cpu就要停止目前的工作来处理这个中断。其实,默认所有的中断处理都集中在cpu0 上,导致服务器负载过高。cpu0 成了瓶颈,而其他cpu却还闲着。
➊ 解决方式1:使用CPU亲和性功能,kafka略过网卡所使用的CPU
➋ 解决方式2: 更换网卡
➌ 通常修改的方式还是有些复杂了,比如,修改
/proc/irq/{seq}/smp_affinity
我们可以直接安装irqbalance,然后执行就可以了。
yum install irqbalance -y
service irqbalance startcpu使用率低linux查看cpu核数,但负载高
cpu id%高,也就是空闲,比如90%。但 load average非常高,比如4核达到10。
分析:load average高,说明其任务已经排队,许多任务正在等待。出现此种情况,可能存在大量不可中断的进程。
使用top或者ps可以看到进程相应的状态。
ps aux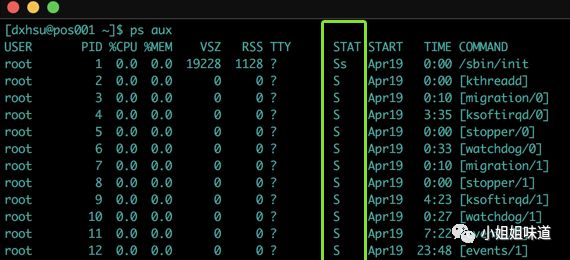
一种情况就是有大量进程处于D的状态,也就是不可中断的睡眠状态,所以很可能是硬件问题。
详见
高频问题:loadload代表的是啥
说句白话,load代表的就是你目前系统进程的排队情况。
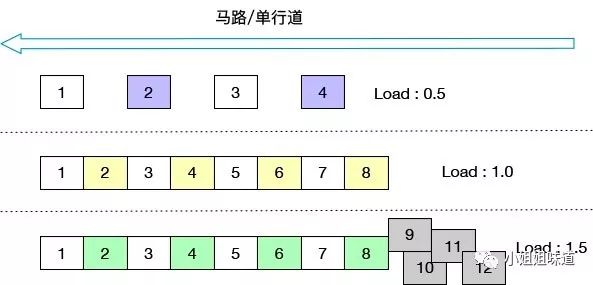
如图,以单核为例,将CPU资源抽象成一条单行马路。则会发生三种情况:
➊ 马路上的车只有4辆,车辆畅通无阻,load大约是0.5
➋ 马路上的车有8辆,正好能首尾相接安全通过,此时load大约为1
➌ 马路上的车有12辆,除了在马路上的8辆车,还有4辆交集的等在外面,也就是超出容量了,需要排队。此时load大约为1.5
load为1代表的是啥
针对这个问题,误解还是比较多的。很多同学认为,load达到1,系统就到了瓶颈,这不完全正确。
load的值和cpu核数息息相关:
➊ 单核的cpu达到100%,load约1
➋ 双核的cpu都达到100%,load约2
➌ 四核的cpu都达到100%,load约为4
所以,对于一个load到了10,却是16核的机器,你的系统还远没有达到负载极限。
结尾
此文归属微信公众号「小姐姐味道」,转载注明出处。本篇实际的排查过程较少,因为cpu问题一般都伴随着其他问题。但文中出现的这些命令可不简单,尤其是它们丰富的参数。这些参数,执行一下man,就可以一睹芳容了。比如:
man top当然,也可以这样~
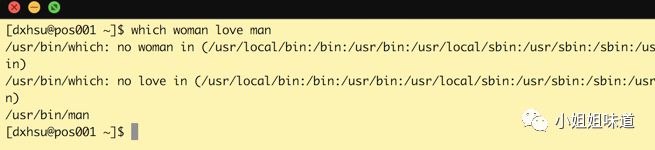
no woman、 no love,果然是一个只有男人的世界!
限时特惠:本站每日持续更新海量展厅资源,一年会员只需29.9元,全站资源免费下载
站长微信:zhanting688


{kind=link}